
why is my model unfAIr?
Published:
 Algorithmic bias is an inherent challenge in machine learning models, particularly in high-stakes applications like credit approval, where fairness is critical. In this blog post, I discuss four key sources of bias in AI models: (i) bias in human decisions, (ii) proxy attributes, (iii) sample selection bias and (iv) algorithmic objectives. Each source of bias is accompanied by an empirical example from model-based credit approval.
Algorithmic bias is an inherent challenge in machine learning models, particularly in high-stakes applications like credit approval, where fairness is critical. In this blog post, I discuss four key sources of bias in AI models: (i) bias in human decisions, (ii) proxy attributes, (iii) sample selection bias and (iv) algorithmic objectives. Each source of bias is accompanied by an empirical example from model-based credit approval.
I believe that no single machine learning model trained on real-world data is free from algorithmic bias and discrimination. All models discriminate, and our job as data scientists and developers is simply to understand and mitigate bias – not more and not less.
At spotixx , an upcoming FinTech company among the Top50 fastest growing startups according to Sifted’s Germany leaderboard, we develop AI solutions for banking and anti-financial crime. With the recent adoption of the EU AI Act, AI models for high-risk systems such as models evaluating individuals’ creditworthiness are legally required to mitigate and prevent discrimination stemming from their predictions against of a whole range of vulnerable groups. But how to do that?
➡This article highlights four different sources of bias in an AI model towards marginalized groups without it ever being intended during model development and without the sensitive attribute being used for modeling using examples from credit approval.
Introduction
From automated detection of financial fraud over credit approvals until the hiring process within major HR departments, machine learning-based artificial intelligence is everywhere. Often, stakeholders of AI systems promise themselves an increase in the fairness of decisions when relying on automatized rather than human-driven decision making. After all, a large number of unconscious psychological biases have historically resulted in discrimination based on sensitive attributes such as gender, ethnicity or nationality when relying on humans rather than carefully calibrated AI systems.
“If I incorporate no sensitive attribute that my AI model could discriminate against into my model, my company will be protected against bias against marginalized groups”, might be what a naïve stakeholder or developer of an AI model reassures themselves in the design phase of a new application.
However, as a large strand of literature has outlined, there are manifold reasons of why your model can be systematically biased against a certain marginalized group without this ever being intended by any developer and without the sensitive attribute being used for modeling in any way. In addition, the stakes are on the rise: With the recent adoption of the EU AI Act, requirements for model deployers regarding algorithmic fairness are growing, and legal sanctions are awaiting those that fail to account for non-discrimination through their AI models.
Four Sources of Bias
Bias in human decisions that the model is trained to replicate
🔎 This is probably the most obvious source of bias and the one that is most often thought of. Any AI system that is trained to pick up and replicate complex patterns within a set of data can be biased if the underlying data generating process was biased itself. If, for example, a model is trained to approximate a target function that replicates human decision-making in the past with the goal of independently performing such decisions in the future, any human biases that are inherent to the data might be picked up by the model as well.
Example: Credit approval. Imagine a financial institution in which bank clerks have historically decided over the granting and conditions of credits or loans. Approvers unconsciously might have granted approval to members of a priviliged group with a higher propensity than to marginalized groups – a pattern that is picked up on replicated by your machine learning model.
Bias through proxy attributes
🔎 Even if the underlying data generating process includes biased decision-making that systematically disadvantages one marginalized group, the question remains how a machine learning model would pick up on this bias if the sensitive attribute defining the protected group like ethnicity is not included in the model. The answer is: 📢proxy attributes.
Example: Credit approval. Imagine a development team cautiously not including a protected attribute like ethnicity into their machine learning model, but providing the model with information on the individuals’ location such as district information or street address. As different marginalized groups do heavily form geographical clusters even within one city, information on the applicant’s ethnicity is hiddenly encoded in seemingly “neutral” socio-demographic attributes like city district. On the surface, a trained model may make decisions based on district-level information. What is actually happening is decision-making based on the protected attribute.
Sample selection bias
🔎 We are now moving to the even more disguised sources of algorithmic bias – although their impact may be huge. Again, this sort of bias relates to the way our data set used for AI model training is constructed. Other than in the first source of bias, we do not refer to biased human decision-making! This source of bias can even exist when the decision-making process that the model is trained to replicate was completely fair! Sample selection bias refers to those individuals of the marginalized group that would have received a positive outcome on the outcome variable systematically appearing in our dataset less often than those marginalized individuals that would receive a negative outcome.
Formally, this can be expressed as:
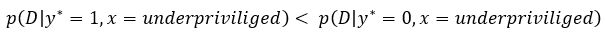
where P(D) is the probability of an individual to be observed in our data, y* is the latent outcome an individual would observe once it is part of the data and x refers to the sensitive and protected attribute.
Example: Credit approval. Imagine a certain bank which was in the news for being exposed of racial discriminiation in credit approval rates in the past. Well-informed high-income individuals from a marginalized group with a lot of optionality might avoid that bank and self-select out of being observed in the data – by simply approaching other credit institutes that seem more trustworthy to them. Badly-informed low-income individuals from the same marginalized group do either not possess this information or do not have the optionality to freely choose their credit house and hence still appear unfiltered in our data. Hence, even when the decision-making across actual applicants is completely fair now, marginalized individuals with low chances of a positive outcome are systematically observed more frequently than marginalized individuals with high chances of a positive outcome – a pattern that is picked up by our machine learning model.
Bias through algorithmic objectives in model training
🔎 The final and most subtle form of bias may be the hardest to detect – and can again appear even in the absence of systematically different treatments of marginalized groups during the data generation and even in the absence of sample selection bias!
This type of bias simply refers to the fact that for model training, in almost every case, a loss function (that measures the global quality of our model) is used which simply sums up all aggregated prediction errors across all individuals. When the goal is to minimize the prediction errors as a whole and if the prevalence of members of the privileged group is (a lot) higher than the prevalence of members from the underprivileged group, the model will over-focus on error reduction within the majority rather than the minority group.
As a result, this will lead to an AI model that reliably works well on members of the majority class – but shows poor performance within the minority group. This will have little effect on measures about your overall model performance, which might still look very fine. But it will have a huge effect on members of vulnerable groups, which may systematically be disenfranchised.
Example: Credit approval. In your data, 98% of observed datapoints might stem from healthy individuals, while 2% of datapoints are generated from people with a diagnosed disability. While applications of the majority group are subject to a well-calibrated and reliable artificial intelligence model, applications of the minority group are subject to the roll of a dice, which systematically violates their equal treatment.
Outro
This was our walkthrough of the different ways your machine learning model can exert bias and discrimination without any developer or data scientist having intended to drive the model’s decision making on the basis of a protected attribute.
You already have an AI model and want to be able to measure whether it exerts discrimination, the type of discrimination that can be observed and the extent of bias? This will be covered in the next article of this series.
What are your experiences of why machine learning models exert bias? What are additional sources of discrimination that are not discussed here?
Literature:
Pessach, D., Shmueli, E. (2023). Algorithmic Fairness. In: Rokach, L., Maimon, O., Shmueli, E. (eds) Machine Learning for Data Science Handbook. Springer, Cham.
Barocas, S., Hardt, M. and Narayanan, A. (2023). Fairness and Machine Learning: Limitations and Opportunities. MIT Press, Cambridge.